06 Jun 2020
Like most people, I’d prefer to see our communities come together, make things, learn, build, enjoy art, and coexist in harmony with each other and nature. But we obviously aren’t there yet.
Instead we have a reality in which American billionaires increased their wealth by $434B while the rest of us have struggled to survive a global pandemic and economic depression. Where 1000 people each year are killed by increasingly militarized police forces, where black people are killed while sleeping in their homes, jogging, driving.
Power Asymmetry and Violence
The murder of George Floyd set off a cascade of demonstrations spawning uprisings in every state in the US and in many countries around the world in the spring of 2020. The unrest renewed a discussion about the morality and efficacy of the tactics used by people in the streets:
- Isn’t property destruction bad?
- Isn’t violence bad?
- Why are they destroying their cities?
Setting aside the problems with these questions, I think most people would agree that, in a vacuum, person A inflicting harm on person B is immoral.
But, in the real word, we have to consider the mountains of inequality between actors: some have more wealth than entire nations, some have ancestry from centuries of chattel slavery, some are killed by agents of the state, some profit by closing community hospitals, some have legal teams, some can’t post bail, some can’t afford insulin, some poison the air that others breath, some write laws, some can’t vote, some work from home, some are essential workers, some suffer under broad systemic racism, others benefit from it.
This power asymmetry, in my view, is what matters most when we think about what tactics are strategic and moral toward the goal of achieving positive change.
First, let’s assume that the behavior of the system, with respect to power, follows a couple rules:
- agents with power benefit from the status quo and by squeezing more power out of the system
- agents with power don’t voluntarily relinquish power
- money is power
Given this, if demands on an unjust power structure can be ignored, they will be. Gains for regular people happen when their demands and actions can’t be ignored by the status quo and established power. This is why direct action that threatens, inflicts harm, costs, or at least inconveniences our opponents works. This is why it is effective to block traffic and shut down oil pipeline worksites. It stops business-as-usual, demands attention, and increases negotiating power.
I think much of the vandalism, broken windows, burned police stations, and looting is the manifestation of valid disgust and anger at an unjust system. Regardless of how valid or logical a human response one considers these uprisings, the fact that they are not under control by the beneficiaries of the status quo is what makes them potent and effective.
Peaceful Protest
Imagine a peaceful march that poses no inconvenience to those standing in the way of police reform. One that obeys the curfews imposed by the police, that stays on the sidewalks, and doesn’t affect the rush hour traffic (one that offers a Pepsi to a cop). Organizers can try to control the narrative and hope that the media reports sympathetically, that the police might be interested and open to listening to the activists’ speeches. Maybe the police chief will see the signatures on the petition and reevaluate their life’s work. Maybe its possible to appeal to the morality of officials to find legislative solutions.
I’m not suggesting that there aren’t alternatives to burning police cars and looting Walmarts. There are. But I do think we’ve waited long enough for demands to be heard and for police to stop murdering black people.
Our Opponents are Ruthless
If the tactics taken by the 2020 uprising seem too violent, consider the tactics used by our opponents: tear gas, rubber bullets, bullets, tanks, drones, mass surveillance, from Jim Crow, to the assassination of Fred Hampton, Martin Luther King Jr., lynchings past and present. Consider the lengths Charles Koch was willing to go to dismantle labor and environmental protections, and the ruthlessness of Jeff Bezos, the dishonesty of big tobacco, Exxon Mobile. Our opponents are not sitting idly by, patiently waiting to cast their ballot every 4 years. They are hardcore. They are radical activists fighting violently for power and self-preservation.
We’ve been in an unfair fight for decades - unless we recognize that and fight back we are going to continue to lose.
02 May 2020
I’ve tried several times to develop a writing habit with varying levels of
success. But, after about a full year slump, I again forgot how to update my
blogo.
Over the years, my writing has lived in various types of infrastructure
(Myspace, Wordpress, notepad++, etc.) always tracking along with my evolving
coding tastes. In my PHP phase I was trying to blog with Laraval, for example.
The second-most recent iteration was the magic unicorn of Django, tracking
along with my ongoing love for Python.
Keep it simple
Somewhere along the line I grew frustrated with mental overhead necessary to
remember how to use Django anytime I felt inspired to write. This was exacerbated
by my writing inconsistency.
So, I had the brilliant idea to make things extremely simple: write in
markdown and host with GitHub pages. I use both tools daily, so what could
go wrong?
Then after many moons I forgot that I migrated my blog to this brilliant, simple
system. Over the next two years I was left intermittently trying to remember how
to log into the Django admin panel in an Django app that didn’t exist.
Yay!
22 Jul 2017
In a recent post, I outlined a process that aims to capture the dynamics of the media landscape by taking a snapshot of news headlines every 15 minutes. The database has been quietly growing for about a month now, receiving data scraped from 19 media organizations’ RSS feeds while the world goes about its business. Even though we only have a sliver of headlines history to work with (about 30 days), we’re ready for some analysis.
Let’s start by taking a look at an example document in the MongoDB database representing a snapshot of USA Today’s RSS feed on June 12, 2017:
{
"_id": ObjectId("593e13134a5ac4327d88619c"),
"datetime": datetime.datetime(2017, 6, 12, 4, 5, 32, 832000),
"source": u"usa_today",
"stories": [
"'Dear Evan Hansen' wins six Tony Awards, including best musical",
"Penguins have become NHL's newest dynasty",
"First lady Melania Trump, son Barron officially move into the White House",
"E3 2017: The 5 biggest reveals during the Xbox event",
"Penguins repeat as Stanley Cup champions",
"Homophobic slur aimed at U.S. goalkeeper Brad Guzan by Mexican fans at World Cup qualifier",
"Ben Platt's reaction is the best GIF of the Tonys Awards",
"Puerto Ricans parade in New York, back statehood",
"Delta ends theater company sponsorship over Trump look-alike killing scene",
"U.S. earns rare tie vs. Mexico in World Cup qualifier at Estadio Azteca"
]
}
Within the document, we see a list of stories (i.e. news headlines) alongside the source (USA Today) and the datetime when the headlines were observed. As noted above, these snapshots are created every 15 minutes with data from the RSS feeds of 19 media organizations (see the list of feeds here). At the time of writing, there are 29,925 of these snapshots in the database with headlines starting on June 12, 2017 (note: I lost all data between June 13 and July 5).
Querying Headlines with PyMongo and Pandas
In order to interact with the data, we construct a function, query_rss_stories() that wraps up the process of connecting to MongoDB, querying using the aggregation framework and regex, and organizing the results in a Pandas dataframe:
def query_rss_stories(regex):
#connect to db
client = MongoClient()
news = client.news
headlines = news.headlines
#query the database, create dataframe
pipeline = [
{"$unwind":"$stories"},
{"$match":{"stories":{'$regex':regex}}},
{"$project":{"_id":0, "datetime":1, "stories":1, "source":1}}
]
#unpack the cursor into a Dataframe
cursor = headlines.aggregate(pipeline)
df = pd.DataFrame([i for i in cursor])
#round the rss query datetimes to 15mins
df.datetime = df.datetime.dt.round('15min')
raw_stories = df.set_index(['datetime'])
return raw_stories
As an example, we’ll search for stories related to China:
stories = query_rss_stories('China')
stories.sample(n=5)
|
source |
stories |
| datetime |
|
|
| 2017-07-20 14:00:00 |
breitbart |
Report: U.S. Bans Prompt American Allies to Bu... |
| 2017-07-14 05:45:00 |
upi |
India rejects China's offer to mediate Kashmir... |
| 2017-07-13 00:15:00 |
wsj_opinion |
How to Squeeze China |
| 2017-07-07 19:00:00 |
abc |
US bombers fly over East and South China Seas |
| 2017-07-12 19:15:00 |
reuters |
China dissident Liu's condition critical, brea... |
The stories dataframe contains all headlines related to China from all of the new sources starting around July 6. For every hour that a headline is live on a particular RSS feed, four entries will be found in the stories dataframe (since the snapshots are taken at 15-minute intervals).
Next, we unstack the data and count the number of China-related headlines found at each time step:
def create_rss_timeseries(df, freq='1h'):
#unstack sources and create headline_count time series
ts = df.assign(headline_count = 1)
ts = ts.groupby(['datetime', 'source']).sum()
ts = ts.unstack(level=-1)
ts.columns = ts.columns.get_level_values(1)
#set time step
ts = ts.assign(datetime = ts.index)
ts = ts.groupby(pd.Grouper(key='datetime', freq=freq)).mean()
return ts
#daily time series of China headline counts
ts = create_rss_timeseries(stories, freq='1d')
To visualize, we create a stacked bar chart of China-related headline counts across all media organizations:
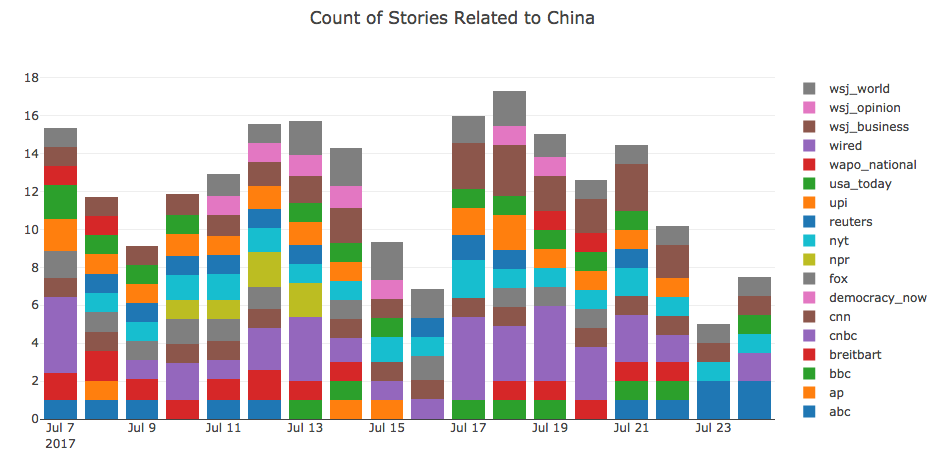 Here, we can see that each day between July 7 and July 23, 2017, between 7 and 17 China-related headlines were found from 18 media sources. Sort of interesting, but what about a more volatile topic?
Here, we can see that each day between July 7 and July 23, 2017, between 7 and 17 China-related headlines were found from 18 media sources. Sort of interesting, but what about a more volatile topic?
Let’s take a look at the volume of headlines related to “Trump Jr”. We’ll also increase the resolution thats visualized so we can see how the media coverage evolves each hour:
jr_stories = query_rss_stories('Trump Jr')
jr_ts = create_rss_timeseries(jr_stories, freq='1h')
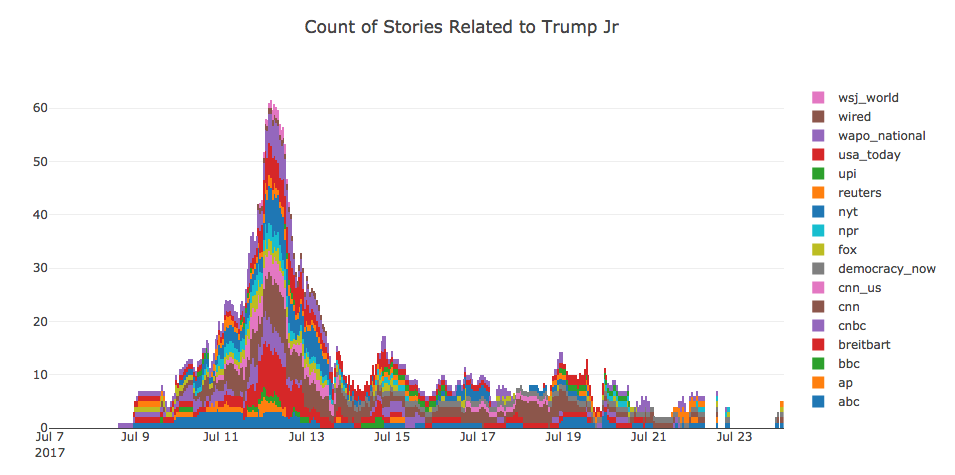 Now we’re seeing a major event play out.
Now we’re seeing a major event play out.
Interpretations and Future Work
Recording periodic snapshots allows us to observe how the media’s interest in a particular topic changes over time. For example, a topic that’s discussed simultaneously in multiple articles by many media organizations must be especially important at a given point in time. Similarly, an issue that is featured throughout the RSS feeds for many days are likely more significant than stories that come and go within a few hours. One can think of these dynamics like the intensity and duration of rainfall events: is there are drizzle or a deluge of articles, and for how long are the stories pattering down?
I’ve only scratched the surface, but there is a lot more I’d like to investigate now that I have a handle on the data. Future Work:
- measure the proportion of attention given to particular topics
- quantify the differences in reporting between media organizations
- compare media attention to objectively important and quantifiable topics:
- casualties of war
- bombings, shootings
- environmental disasters
- natural language analysis
- differences in sentiment on particular topics
- differences in sentiment between sources
- identify any patterns between left- and right-leaning sources
- host data on public server and/or data.world